06 — Rock fidelity: an evolution
| *Chaotic Curiosity | regolith series* |
This series was built twice. The first time, the rocks were crude — smooth, low-poly icospheres that read, charitably, as gray eggs half-buried in the dirt. They worked: the model learned to find them, domain randomization bought a clean +0.099 rock-IoU, and the sim-to-real evaluation showed a real but survivable gap. It was a tidy success story.
So we did the obvious thing. We made the rocks photoreal — noise-displaced basalt boulders, rough and pitted and sub-angular, the kind of geometry you’d be proud to put in a render reel. The synthetic benchmark went up. And the real-world transfer got worse. This chapter is the before-and-after: what changed in the geometry, what it did to every number, and the counter-intuitive lesson hiding in the gap between the two builds. It is the most important chapter in the series, because it is the one where the intuitive move was the wrong one.
Before and after: the geometry
Here are the two builds, same scene, same lighting, rocks swapped:

The left is the first build. An icosphere — subdivision-2, 162 vertices — deformed by a handful of sinusoidal lobes, smooth-shaded into a rounded blob. You can count the facets. Nothing about it says “rock” except context.
The right is the realistic build. The same icosphere base, but:
- Subdivision scaled to on-screen size. A far-field pebble stays at subdivision-2 (162 verts); a near boulder gets subdivision-4 (2,562 verts); a hero boulder gets subdivision-5 (10,242 verts / 20,480 faces). Polygons go where the camera can see them. A full scene runs ~0.7 M triangles.
- Multi-octave 3-D noise displacement. Each vertex is pushed along its radial direction by four stacked terms: coarse fractional-Brownian-motion lumps for the overall blocky form, a ridged facet term (
1 − |fBm|) that turns noise valleys into the sharp creases and planar fractures of broken basalt, and medium and fine octaves for surface texture down to the pit scale. The noise domain is sampled anisotropically per rock, so every boulder is a distinct elongated shape rather than a sphere with bumps. - Smooth per-vertex normals. Face normals averaged into shared vertices, which dissolves the faceting into a continuous matte surface.
- A 12-material dark-basalt PBR pool. Per-rock base albedo 0.058–0.130 (darker than the regolith), warm-gray tint, high roughness — tonal variety across the field without a unique shader per rock.
It is, by any visual standard, a large improvement. The rocks look like rocks. That is precisely the problem.
What it did to the synthetic numbers
Same SegFormer-B0 recipe, same three-run size-matched ablation (chapter 03), run on both the old and new rocks. The realistic geometry lifted every score:
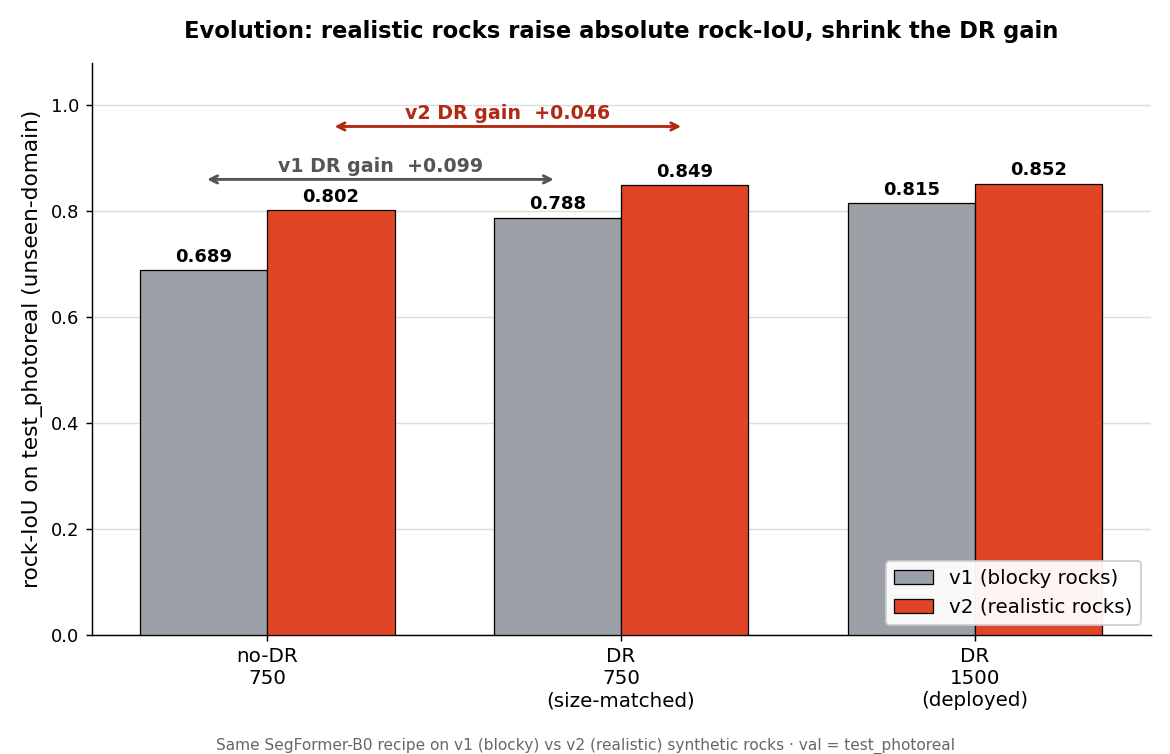
| Run | v1 (blocky) | v2 (realistic) |
|---|---|---|
| no-DR, 750 | 0.689 | 0.8025 |
| DR, 750 (size-matched) | 0.788 | 0.8486 |
| DR, 1500 (deployed) | 0.815 | 0.8521 |
| size-matched DR gain | +0.099 | +0.046 |
Read straight, this is a triumph. The deployed model went from 0.815 to 0.852 rock-IoU. Even the un-randomized baseline leapt from 0.689 to 0.8025. If you stopped at this chart — as a synthetic benchmark invites you to — you would conclude the upgrade was an unqualified win and ship it.
There is one quiet signal in the chart that something subtler is happening: the DR gain shrank, from +0.099 to +0.046, and the more-data gain all but vanished (+0.004 from 750 to 1,500, chapter 03). The realistic rocks are a richer signal in their own geometry — every boulder a distinct eroded shape — so even a no-DR model generalizes much better, leaving less brittleness for domain randomization to fix. Fidelity did part of the job DR used to do alone; the two are partly redundant levers. That is a real and interesting finding. It is also a distraction from the actual headline, which the synthetic numbers cannot show you at all.
What it did to the real numbers
The actual headline is in chapter 04, and it points the other way.
| v1 (blocky rocks) | v2 (realistic rocks) | |
|---|---|---|
Synthetic rock-IoU (dr_1500) |
0.815 | 0.852 ↑ |
| Real Apollo frames: pixels called rock | ~52% | ~83% ↑ |
| Real Apollo frames: pixels called regolith | (substantial) | ~4% ↓ |
| DR vs no-DR on real | DR predicts less false rock | DR predicts more false rock |
The realistic build scores higher on synthetic data and floods real lunar regolith with false rock — calling ~83% of every real Apollo frame “rock,” up from ~52% (v1 per-frame data). It barely finds any traversable ground at all (~4% regolith). And domain randomization, which reduced false rock on the crude build, now increases it on every one of the seven real frames. The synthetic arrow points up; every real arrow points the wrong way.
The mechanism, in one line: the texture that made the rocks look real — rough, gray, bumpy, matte basalt — is the same texture that defines real lunar regolith at photographic resolution. The crude blobs were visually distinct from any plausible soil, so the model learned a boundary between “blob” and “ground.” The realistic rocks erased that distinction: the model’s most generalizable cue became “rough gray bumpy texture = rock,” and on real film, regolith is rough gray bumpy texture. The boundary collapsed, and real soil flooded across it. Chapter 04 has the overlays — a wall of red — and the per-frame counts.
The crude rocks, in other words, were accidentally protecting us. Their very lack of realism kept the rock and regolith classes far apart in appearance. Realism closed that gap in the simulator and, by doing so, taught the model a cue that fails catastrophically in the world.
The lesson
This is the spine of the whole series, and it is worth stating without hedging:
Higher fidelity and a higher synthetic score did not buy better real-world transfer. They cost it.
Three things follow, and they generalize well past lunar rocks:
-
Synthetic metrics can mislead. A benchmark rendered by the same engine that produced your training data rewards you for fitting that engine’s conventions.
test_photorealwas a genuine unseen-domain split — different sun, albedo, terrain, lenses — and the realistic model beat the crude one on it cleanly, 0.852 to 0.815. It was still measuring the wrong thing. The only number that mattered, the one with no ground truth and no clean IoU, was on real pixels — and it moved the opposite way. -
Base fidelity and domain randomization both shape sim-to-real, and they interact. They are not independent knobs you can turn up blindly. Raising fidelity lifted the floor and shrank DR’s contribution (the +0.099 → +0.046 story); it also changed what the model treated as invariant, and domain randomization then amplified that invariant — which was helpful when the invariant was good (v1’s shape cue) and harmful when it was the bug (v2’s texture cue). You cannot reason about one lever without the other.
-
Naive realism can backfire — so you must test on real data. “Add more detail, it should help” is a reasonable instinct and, here, exactly wrong, because the detail we added was the specific feature that confuses the real classes. There was no way to know that from inside the simulator. The synthetic score said “better.” Only seven real photographs, with no labels and no IoU, said “worse” — and they were right.
None of this means the realistic rocks were a mistake to build, or that synthetic data doesn’t work. It means the deliverable of this project is not a deployable lunar hazard model — it is an honest, reproducible demonstration of a failure mode that is easy to walk into and hard to see: the better-looking, better-scoring simulator producing the worse real-world model. A model you would actually fly needs real labeled lunar imagery in the loop to catch exactly this. That is the thing synthetic data reduces the need for, and — this chapter is the proof — never fully eliminates.
What you’ve built
This is the turning point of the series — not the end of it. The diagnosis in this chapter (the realism was on the wrong surface) became the hypothesis for v3, where moving the fidelity onto the ground finally dropped the real flood; that is chapter 07. The arc through this chapter, chapter by chapter:
| Chapter | What you built | The honest number |
|---|---|---|
| 00 — Primer | The map: semantic segmentation, synthetic data, the sim-to-real gap, domain randomization, the DGX Spark | — |
| 01 — The lunar stage | A procedural OpenUSD scene: regolith heightfield, realistic noise-displaced basalt rocks, sun, dome, rover camera | First pixel-accurate segmentation mask |
| 02 — Domain randomization | A Replicator pipeline generating 2,550 labeled frames across three splits — DR, no-DR, unseen-domain test | 1,500 / 750 / 300 frames; rock class 1–8% |
| 03 — Training | SegFormer-B0 fine-tuned on synthetic data; honest size-matched ablation isolating DR from dataset size | +0.046 rock-IoU from DR (0.8025 → 0.8486); DR-1500 ceiling 0.8521 |
| 04 — Sim-to-real | Transfer evaluation on 7 real Apollo photographs — no cherry-picking, no fabricated IoU | It floods: ~83% of real pixels called rock (up from ~52%); DR makes it worse |
| 05 — The render | 1920 × 1080 RTX flythrough with live dr_1500 hazard overlay |
Clean in-distribution overlay (0.852) — the same flattery the benchmark gives |
| 06 — Rock fidelity | The v1→v2 evolution: crude rocks made photoreal, and the honest tradeoff that followed | Synthetic ↑ (0.815 → 0.852), real ↓ (52% → 83% flood) |
The honest bottom line: we made the synthetic rocks photoreal. The synthetic benchmark went up — rock-IoU 0.815 → 0.852. Real-world transfer got worse — the model now floods ~83% of real Apollo pixels with rock, up from ~52%. Higher fidelity and a higher synthetic score did not mean better real transfer; they meant worse. The cause is concrete: photoreal rocks (rough, gray, bumpy) collapsed the rock-vs-regolith boundary toward “any rough gray texture is rock,” and real lunar regolith is exactly that at photo resolution. Synthetic metrics can mislead; base fidelity and domain randomization both shape sim-to-real and interact; naive realism can backfire. The only way to know is to test on real data — which is the entire reason this chapter exists.
What the series does prove, mechanically: you can close a complete physical-AI perception loop — scene authoring, labeled dataset, trained segmentation model, sim-to-real evaluation on real imagery, cinematic render with live inference — on a single 128 GB machine, in under a week of compute, twice over, and learn something real from the comparison. The loop runs end to end. The lesson it surfaced is the deliverable — and it is also the lever for the next build.
Because this failure is not the last word. Read the mechanism once more — the texture shortcut existed only because the ground was smooth while the rocks were rough — and it tells you exactly what to try next: make the ground realistic too. Chapter 07 does that, and the real flood finally drops.
Continue to 07 — Realistic ground: the sim-to-real lever.